Content Modeling and Data Design with Sanity.io




Reconsidering content modeling at a data level for egghead to allow for more
flexible collaboration and design has been an ongoing, long-term challenge
. Since migrating our primary UI to Next.js, features like serverless functions and quick access to flexible server-side rendering have allowed us to consider new options. One of the tools that we've chosen is sanity.io, a content modeling and design service layer that helps us layer valuable contextual metadata on top of our existing data model.
Where we were
We have two APIs available that access the same underlying postgres database. One is a REST API that has nice hypermedia capabilities and is pretty slow built on top of jbuilder. The other is a well-formed GraphQL API that is much more performant and provides immediate and direct access to slices of the data we want.
Both of these APIs are fairly 1:1 with the underlying database and define what I've come to look at as a "hyper specified" content model that got the job done, but has been a serious constraint that we've had to live with for many years 😅
Both of these APIs take 30-40 minutes to deploy and require fairly deep knowledge of Rails, GraphQL, and Ruby.
The deeply technical API layer provides a massive barrier to entry and because everything is very closely tied to the database, changes can have rippling side-effects that were never intended.
Resources and Collections
When egghead was a sparkling fresh app I started out modeling what was obvious at the time.
Lessons: people come to egghead to watch lessons, not videos.Series: sometimes people want to watch a series of lessons (not videos)
Later we added Playlists, called them collections, and then decided that both a series and a playlist were actually courses. lol
Fundamentally what we are dealing with are resources and collections, where a collection is just a resource with a list of other resources referenced.
Where we want to be
We want to build a digital garden. We want to curate, update, associate, and present relevant resources to users so that they can quickly find what they need and reach the outcomes they desire.
For us, this requires a "metadata" layer that sits above the APIs without a rigid schema or the need for deep levels of technical know-how to operate.
For years we've done this by creating various JavaScript/JSON data structures in flat files that get compiled in with the application.
You can see an example here where we keep various metadata about egghead courses. Another example is this one that describes the data for our curated home page.
This honestly isn't bad, but it's still tedious, error-prone, and requires us to use IDEs as UI for updating content. Not ideal, but very flexible.
Content Modeling with Sanity.io
After exploring several alternatives and living with the flat json files for years, a product has emerged that checks most of the boxes that we need. Deep flexibility. Ease of use. An incredibly nice authoring experience and a welcoming team and community.
Sanity.
What first stands out to me about Sanity is that it installs into your project via their CLI (command line interface). This was so different to me that it was hard to understand at first, but once I got the CLI installed with a default starter dataset, it started to make sense.
Once I read the docs and started to explore the flexible potential it really clicked.
The core atom of our emerging system is the resource type. You can see how it evolved here on Github if you're interested.
A resource as a type property. It can describe any of the content types that we deal with at egghead, and we can always add additional types as needed. Types are resources like podcasts, videos, courses, collections, and features.
We are able to sync our existing database with Sanity, so all of the items that are in postgres are represented in Sanity. It could potentially replace a huge portion of our data needs, but for now, we are keeping them synced manually.
Modeling resources, not layout
What's stood out as important for us is that we want to create a robust resource model that describes and augments core content. We want it to be flexible and longer-lived than a typical layout and withstand heavy changes to design and presentation.
We want our data to work in different contexts across our app (and beyond) so we are intentionally avoiding any layout concerns in the content model. The data describes what, not where, the content will ultimately be displayed.
This means that instead of modeling pages, we are describing content and layering on supporting assets and metadata that allow us to choose content that's appropriate and relevant, when and where you need it.
A Practical Example
To illustrate, on the egghead homepage we present a large banner that showcases a resource, a new course, an event, etc
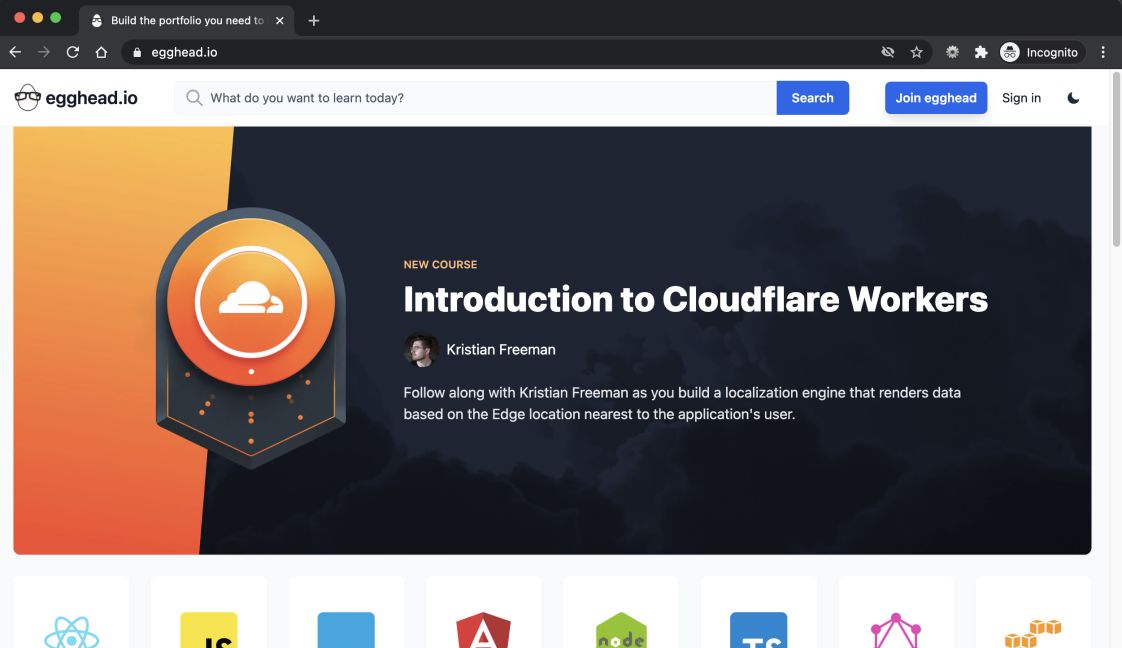
It's represented in home-page-date.ts as a property called jumbotron
This works pretty well. When we want to swap it out we just go in and enter new data. It's not great though, and requires a deploy.
When I sat down to model this in Sanity, the first impulse was to create a document called "Home Page Jumbotron". Then I can query Sanity using their GROQ query language on the server and create a similar data structure to render the header graphic:
This is getting better. It produces the same data structure, and we can now live-update the header component inside of Sanity Studio and don't need to redeploy. While that is creating documents that are tied to specific pages, it isn't modeling data for layout and gives us a ton of flexibility.
If this is your first time seeing GROQ it might look strange, but it's actually a fascinating and relatively simple way to query data. Here's the official GROQ Cheat Sheet that gives a great overview.
Taking that a step further I can consider replacing the entire home-page-date.ts with a loader that looks like this using what is referred to as an "outer reflection" in Sanity's GROQ query language:
This approach would allow me to add a structured query to load the data for each section, feature, and call to action (CTA) on the home page of the site and give the team the ability to update, curate, and tend our collaborative digital community garden without requiring a deploy of the front end.
If we want to change the design or switch out the data we are loading, that starts to become simpler as well.
We are able to layer assets on top of our resources with ease and allow our designers and editorial team members to have more collaborative creative control over the resulting page.
Where we are headed....
This is a great start. Sanity has a lot of potential and we haven't even begun to scratch the surface. We are going to be tuning our content model and importing more data first. Then we will start to explore Sanity's Structure Builder, which can be used to design content pipelines and workflows that give us even more flexibility in our digital gardening process.
Having a bespoke, contextual, lovely content authoring tool at our disposal is exciting, and I'm looking forward to digging in more.
Questions? Please feel free to ask on twitter!